HTTP Session 攻击与防护
Cookie的基本概念
Cookie 是网站在浏览器中存放的資料,內容包括使用者在网站上的偏好設定、或者是登入的 Session ID。网站利用 Session ID 來辨认访客的身份。
当用户访问某一站点时,浏览器会根据用户访问的站点自动搜索可用的cookie,如果有可用的就随着请求一起发送到了服务端。每次接收到服务端的响应时又会更新本地的cookie信息。
客户端和服务端的这种联系必然是需要有时间的规定的,所以需要定期清除session。这个问题就需要在两方面考虑了,一个是清除服务端session文件,一个是清除客户端的cookie信息,因为两者都各保存着一半的信息。
Cookie 既然存放在 Client 端,那就有被窃取的風險。例如透過 Cross-Site Scripting(跨站腳本共计,又稱 XSS),攻击者可以輕易窃取受害者的 Cookie。如果 Cookie 被偷走了,你的身份就被窃取了。
Session 共计手法有三種:
- 猜测 Session ID (Session Prediction)
- 窃取 Session ID (Session Hijacking)
- 固定 Session ID (Session Fixation)
Session Prediction (猜测 Session ID)
Session ID 如同我們前面所說的,就如同是會員卡的编号。只要知道 Session ID,就可以成為這個使用者。如果 Session ID 的长度、复杂度、杂乱度不夠,就能夠被攻击者猜测。攻击者只要寫程序不斷暴力計算 Session ID,就有機會得到有效的 Session ID 而窃取使用者帳號。
分析 Session ID 的工具可以用以下幾種
OWASP WebScarab
Stompy
Burp Suite
观察 Session ID 的亂數分布,可以了解是否能夠推出規律、猜测有效的 Session ID。
防护措施
使用 Session ID 分析程序進行分析,評估是否无法被預測。如果沒有 100% 的把握自己撰寫的 Session ID 產生機制是安全的,不妨使用內建的 Session ID 產生 function,通常都有一定程度的安全。
Session Hijacking (窃取 Session ID)
窃取 Session ID 是最常見的共计手法。攻击者可以利用多種方式窃取 Cookie 獲取 Session ID:
- 跨站腳本攻击 (Cross-Site Scripting (XSS)):利用 XSS 漏洞窃取使用者 Cookie
- 网路窃听:使用 ARP Spoofing 等手法窃听网路封包獲取 Cookie
透過 Referer 取得:若网站允許 Session ID 使用 URL 传输,便可能從 Referer 取得 Session ID
窃取利用的方式如下圖:
受害者已經登入网站伺服器,並且取得 Session ID,在連線過程中攻击者用窃听的方式獲取受害者 Session ID。攻击者直接使用窃取到的 Session ID 送至伺服器,偽造受害者身分。若伺服器沒有檢查 Session ID 的使用者身分,則可以让攻击者得逞。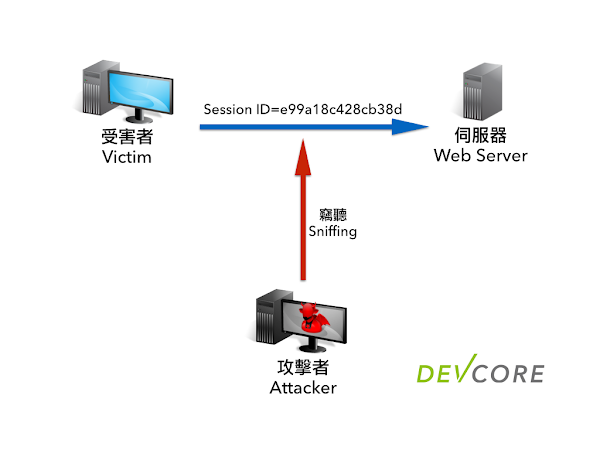

防护措施
- 禁止將 Session ID 使用 URL (GET) 方式來传输
- 設定加強安全性的 Cookie 属性:HttpOnly (无法被 JavaScript 存取)
- 設定加強安全性的 Cookie 属性:Secure (只在 HTTPS 传输,若网站无 HTTPS 請勿設定)
在需要權限的頁面請使用者重新輸入密碼
Session Fixation (固定 Session ID)
攻击者诱使受害者使用特定的 Session ID 登入网站,而攻击者就能取得受害者的身分。
- 攻击者從网站取得有效 Session ID
- 使用社交工程等手法诱使受害者點選連結,使用該 Session ID 登入网站
- 受害者輸入帳號密碼成功登入网站
- 攻击者使用該 Session ID,操作受害者的帳號

防护措施
在使用者登入成功後,立即更換 Session ID,防止攻击者操控 Session ID 給予受害者。
禁止將 Session ID 使用 URL (GET) 方式來传输
Session 防护
每個使用者在登入网站的時候,我們可以用每個人特有的識別資訊來確認身分:
- 來源 IP 位址
- 瀏覽器 User-Agent
如果在同一個 Session 中,使用者的 IP 或者 User-Agent 改變了,最安全的作法就是把這個 Session 清除,請使用者重新登入。雖然使用者可能因為 IP 更換、Proxy 等因素導致被強制登出,但為了安全性,便利性必須要與之取捨。
除了檢查個人識別資訊來確認是否盜用之外,也可以增加前述的 Session ID 的防护方式:
- Cookie 設定 Secure Flag (HTTPS)
- Cookie 設定 HTTP Only Flag
- 成功登入後立即變更 Session ID
- Session 的清除機制也非常重要。當伺服器偵測到可疑的使用者 Session 行為時,例如攻击者惡意嘗試偽造 Session ID、使用者 Session 可能遭窃、或者逾時等情況,都應該立刻清除該 Session ID 以免被攻击者利用。
Session 清除机制时机:
- 侦测到恶意尝试 Session ID
- 识别咨询无效时
- 超时

