中文入门编程指南
官方文档
Real-time Streaming ETL with Structured Streaming in Apache Spark 2.1
背景
Structured Streaming接口在社区2.0版本发布测试接口,主要暴露最初的设计思路及基本接口,不具备在生产环境使用的能力;2.1版本中Structured Streaming作为主要功能发布,支持Kafka数据源、基于event_time的window及watermark功能,虽然还在Alapha阶段,但从实现的完备程度及反馈来看已具备初步的功能需求。
设计理念及所解决的问题
从Spark 0.7版本发布DStream接口及Spark Streaming模块以来,Spark具备流式处理功能且在业界有了一系列应用,但依旧存在一些问题,诟病较多的是如下几点:
- 不支持event_time,按照到达绝对时间切分records组成DStream的方式对很多场景不适合
- 不支持流式window操作
- 不支持watermark,无法对乱序数据做容错
2.1版本的Spark不但解决上述问题,并将Spark Streaming的流处理方式和1.x版本中集中开发的SQL模块、DataFrame\DataSet API相融合,推出Structured Streaming引擎。其设计思路在于将持续不断的上游数据抽象为unbounded table,对流式的处理看作是表中不同部分的数据(complete\append\update mode)进行处理: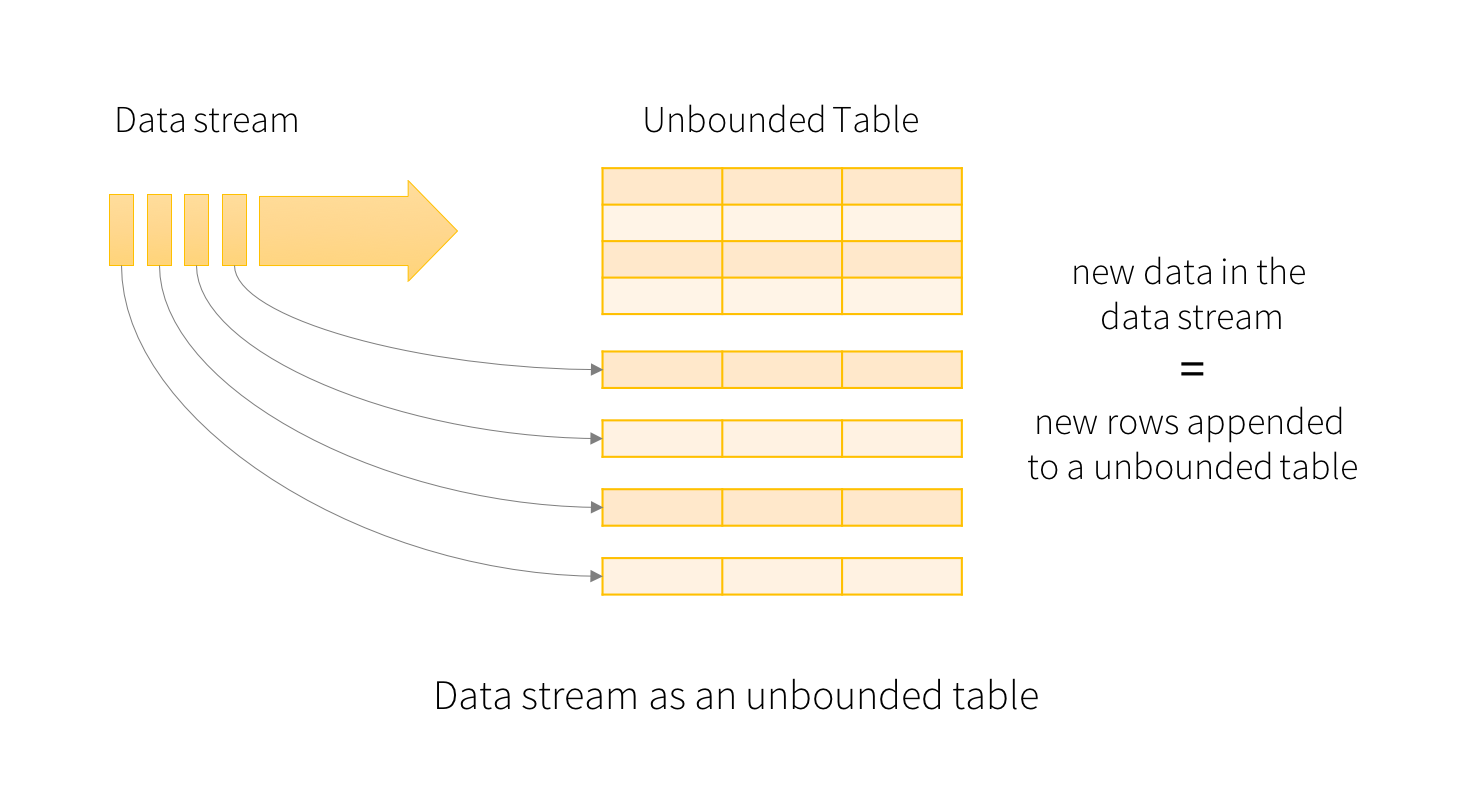
从代码层面看,Structured Streaming代码放在sql模块中,与原有SQL的datasource api、logical plan、physical plan做了诸多兼容操作,将流式处理的上游下游分别抽象为Source与Sink,基于DataFrame抽象出输入输出流DataStreamReader、DataStreamWriter。DataStreamReader中打通datasource api,支持多种上游的读取支持,DataStreamWriter中遵循惰性计算的思路实现多种触发操作及不同类型的写出模式。
Demo for struct streaming
一个完整的struct streaming示例及分布解释如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29import org.apache.spark.sql.functions._
import org.apache.spark.sql.SparkSession
// 与其他spark作业一致,获取build spark session,对应旧版本中的spark context
val spark = SparkSession
.builder
.appName("StructuredNetworkWordCount")
.getOrCreate()
import spark.implicits._
// 创建一个基于stream source的dataframe
val lines = spark.readStream
.format("socket") # 对应基本概念:Source
.option("host", host)
.option("port", port)
.load()
// WordCount逻辑,与dataframe/dataset api用法完全一致,
val words = lines.as[String].flatMap(_.split(" "))
val wordCounts = words.groupBy("value").count()
// 调用dataset的writeStream创建写出流,设置对应的sink mode及类型
val query = wordCounts.writeStream
.outputMode("complete") # 对应基本概念:Output Mode
.format("console") # 对应基本概念:Sink
.start()
query.awaitTermination()
基本概念
Source
Struct Streaming的输入源,每种输入源对应自己的dataSource实现,当前支持如下三种Source:
- File Source: 输入数据源为hdfs目录中的文件,天然支持的文件格式和dataset一致(json csv text parquet),将文件不断mv至指定目录中作为持续数据源
- Kafka Source: 将kafka作为struct streaming source,目前支持的版本为0.10.0
- Socket Source: 将socket输入数据作为streaming source,只用来做调试和demo使用
Output Mode
Output Mode都是对于每次trigger过后的result table而言的 - Complete Mode : 从开始到目前为止的所有数据视为一张大表,query作用于整个表上的结果整体写入
- Append Mode : 从上次trigger到目前为止,不会在发生变化的数据append到最终的sink端
- Update Mode : 从上次trigger到目前为止,发生变化的条目写入到最终的sink端
简单用自带的StructuredNetworkWordCountWindowed实例对比下Complete mode与Update Mode:
数据输入:1
2
3
4[liyuanjian@MacBook~Pro ~]$ nc -l 9999
apache spark
apache hadoop
baidu inf spark
Complete mode output:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24+------+-----+
| value|count|
+------+-----+
|apache| 1|
| spark| 1|
+------+-----+
+------+-----+
| value|count|
+------+-----+
|apache| 2|
|hadoop| 1|
| spark| 1|
+------+-----+
+------+-----+
| value|count|
+------+-----+
| baidu| 1|
|apache| 2|
|hadoop| 1|
| spark| 2|
| inf| 1|
+------+-----+
Update mode output:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21+------+-----+
| value|count|
+------+-----+
|apache| 1|
| spark| 1|
+------+-----+
+------+-----+
| value|count|
+------+-----+
|apache| 2|
|hadoop| 1|
+------+-----+
+-----+-----+
|value|count|
+-----+-----+
|baidu| 1|
| inf| 1|
|spark| 2|
+-----+-----+
Sink
作为struct streaming的下游抽象,sink代表将最终处理完成的dataframe写出的方式,目前支持:
- File sink : 将数据写入hdfs目录,可以支持带partition的table写入
- Console sink : 将数据直接调用dataframe.show()打印在stdout,调试作用,demo中使用的都是console sink
- Memory sink : 将所有下游存储在driver的内存中,抽象为一张表,也只能做调试使用
- Foreach sink : 依赖用户实现ForeachWriter接口配合使用,foreach sink中对每次触发的dataframe,按逐个partition调用ForeachWriter的接口进行处理,可以实现ForeachWriter写入任何需要的下游存储或处理系统,接口如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37abstract class ForeachWriter[T] extends Serializable {
// TODO: Move this to org.apache.spark.sql.util or consolidate this with batch API.
/**
* Called when starting to process one partition of new data in the executor. The `version` is
* for data deduplication when there are failures. When recovering from a failure, some data may
* be generated multiple times but they will always have the same version.
*
* If this method finds using the `partitionId` and `version` that this partition has already been
* processed, it can return `false` to skip the further data processing. However, `close` still
* will be called for cleaning up resources.
*
* @param partitionId the partition id.
* @param version a unique id for data deduplication.
* @return `true` if the corresponding partition and version id should be processed. `false`
* indicates the partition should be skipped.
*/
def open(partitionId: Long, version: Long): Boolean
/**
* Called to process the data in the executor side. This method will be called only when `open`
* returns `true`.
*/
def process(value: T): Unit
/**
* Called when stopping to process one partition of new data in the executor side. This is
* guaranteed to be called either `open` returns `true` or `false`. However,
* `close` won't be called in the following cases:
* - JVM crashes without throwing a `Throwable`
* - `open` throws a `Throwable`.
*
* @param errorOrNull the error thrown during processing data or null if there was no error.
*/
def close(errorOrNull: Throwable): Unit
}
Window
和其他流式系统一样,基于滑动时间窗的数据统计、聚合是必不可少的需求,2.1实现了基于event-time的window定义,接口如下:
1 | /** |
window通常与groupBy算子连用,通过设置dataframe中的timeColumn,windowDuration(window大小),sildeDuration(步长),来定义整个window的行为,如windowDuration = 10min, slideDuration = 5min,则代表由event-time触发每5分钟计算一次,计算的对象是当前window中10min的数据
Watermark
接上述window的介绍,对于任何基于window\event-time的聚合场景,我们都需要考虑对于乱序的过期event-time数据到达的处理行为。watermark用来给用户提供一个接口,让用户能够定义”比当前处理时间慢多久的数据可以丢弃,不再处理”,祥设文档参见:https://docs.google.com/document/d/1z-Pazs5v4rA31azvmYhu4I5xwqaNQl6ZLIS03xhkfCQ/edit#heading=h.yx3tjr1mrnl2

- watermark的计算规则
- 在每次trigger触发计算时,先找到trigger data中的最大(近)event-time
- trigger结束后,
new watermark = MAX(event-time before trigger, max event-time in trigger[步骤1]) - threashold
watermark的限制
watermark操作只能在logical plan中有一个,而且只能应用在从sink出发的单child关系链,简单理解就是处理不了复杂的多留join、union的各自设置watermark